Retrieval augmented generation (RAG) with Streamlit, FastAPI, Weaviate, and Hamilton!
· 19 min read

Off-the-shelf LLMs are excellent at manipulating and generating text, but they only know general facts about the world and probably very little about your use case. Retrieval augmented generation (RAG) refers not to a single algorithm, but rather a broad approach to provide relevant context to an LLM. As industry applications mature, RAG strategies will be tailored case-by-case to optimize relevance, business outcomes, and operational concerns.
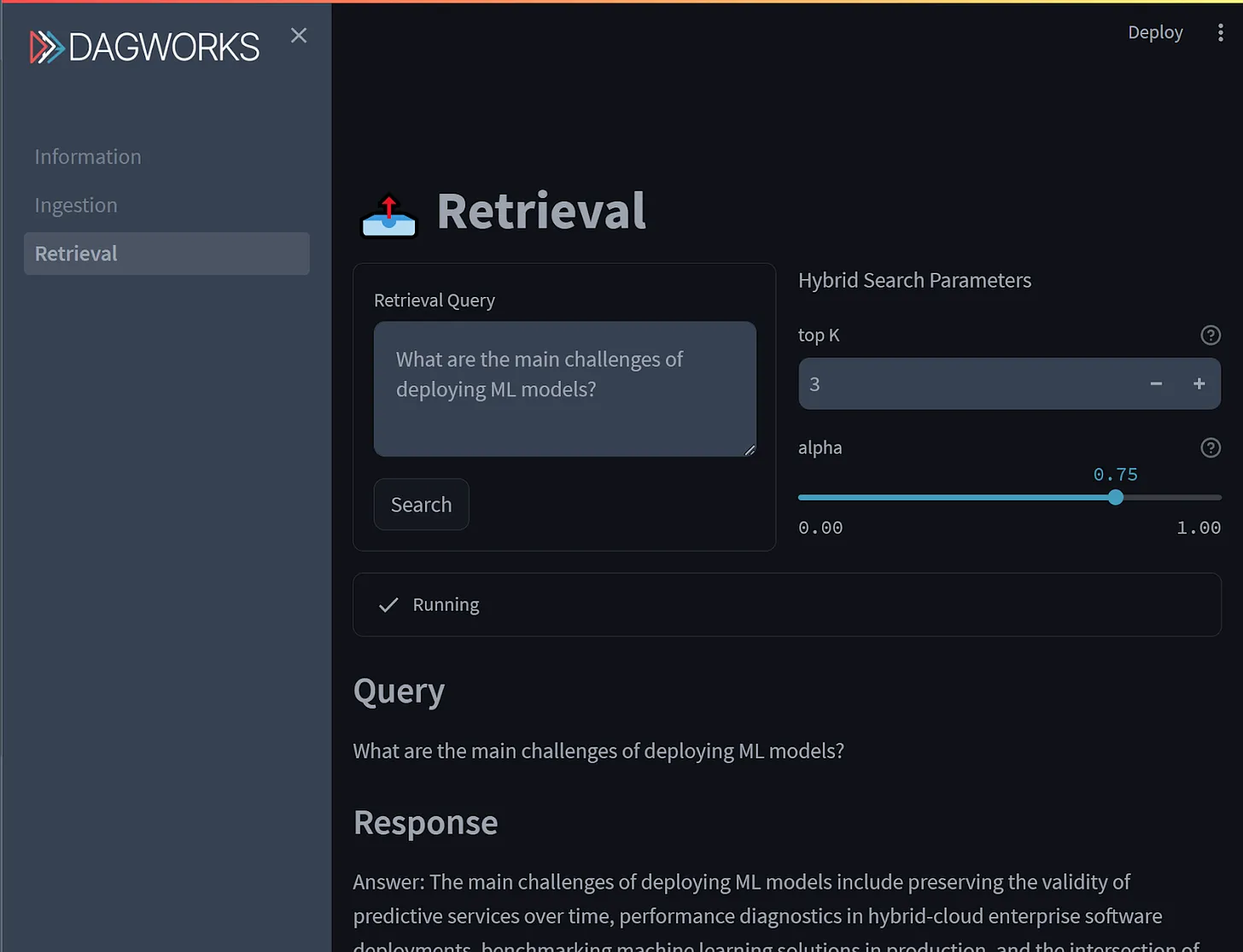
crosspost from https://blog.dagworks.io/p/retrieval-augmented-generation-reference-arch